在现代 AI 编程辅助工具里,项目记忆成为了区分普通工具和企业级开发利器的关键能力。今天我们就以 Trae 为核心,深入解析其项目记忆能力的真实实现,并与主流工具 CodeBuddy、Cursor、Claude Code、Codex/GitHub Copilot、Windsurf 做横向对比。
本文将从五大核心能力切入:
文件化持久项目记忆
全量代码索引与向量检索
RAG 检索增强生成
动态上下文注入
手动规则强化
1. 文件化持久项目记忆 📁
Trae 的真实实现
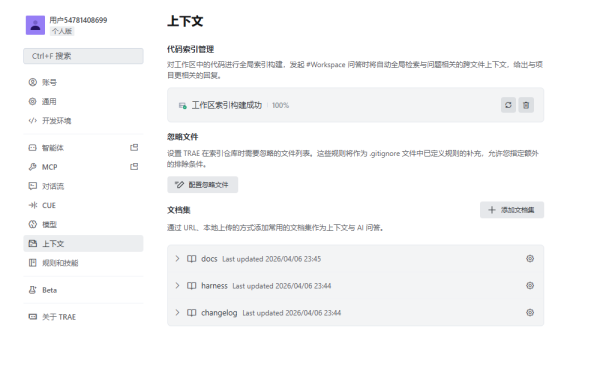
Trae 内置了本地持久化记忆系统(Trae-Mem),以项目为单位保存上下文信息,核心解决会话隔离和上下文窗口限制的痛点,让 AI 跨会话保留项目相关知识,重启 IDE 后记忆不丢失。
存储底层:SQLite(集成 FTS5 全文检索功能,支持 JSON 列存储非结构化元数据),部署零配置,无需依赖重型数据库,仅用轻量架构实现高效记忆存储与检索。
记忆类型:
项目全局记忆:仅在当前项目中生效,覆盖项目整体配置与架构信息
文件夹 / 文件级记忆:精准关联不同层级的代码与文档信息
手动添加的关键规则、注释、设计约束:支持用户主动补充核心信息
全局记忆:可在本地所有项目中生效,记录用户通用编码偏好
机制:采用“记录-沉淀-唤起”的工作流,自动捕捉对话中的项目信息与编码偏好,支持自动更新,当记忆数量达到上限时,将根据引用频率与最近使用时间自动淘汰低价值记忆;同时支持敏感信息隔离,通过<private>标签屏蔽 API Key 等隐私内容,保障数据安全。
相比之下:
CodeBuddy:项目+用户双作用域文件化持久记忆,支持Git共享规则与记忆文件,采用结构化存储,不再依赖简单IDE缓存,关闭会话或重启IDE后记忆可稳定保留。
Cursor:原生本地持久记忆(JSON结构化存储),支持MCP协议扩展,可跨会话召回记忆,搭配插件可实现本地持久化增强,彻底摆脱短期缓存限制。
Claude Code:云端+本地双层文件记忆,隐私优先,支持跨设备、跨会话复用,记忆可提交至Git进行版本控制,新增云端历史追踪功能,可关联Git历史文件。
Codex / GitHub Copilot:企业级持久记忆(预览版),实现仓库级存储,支持跨代理共享,记忆有效期延长至28天,具备完善的项目级持久化能力。
Windsurf:全项目级持久记忆,采用本地索引+会话记忆结合的方式,可实现跨会话完整上下文召回,不再局限于文件片段级记忆。
2. 全量代码索引与向量检索 🔍
Trae 的实现
为了让 AI 对项目有整体理解,Trae 对整个工作区建立代码索引(Code Indexing),构建代码知识图谱 CKG,层级清晰:项目 → 文件夹 → 文件 → 类/模块 → 函数/方法,实现对项目结构的全面把控。
采用本地轻量向量索引,支持语义代码搜索、跨文件/跨函数关联检索、自然语言到代码的精准定位,检索时采用“关键词搜索+时间线回溯”的方式,可还原检索结果对应的上下文场景,提升检索精准度。
同时支持向量索引的基础管理,可基于项目需求灵活调整索引范围,仅针对当前工作区文件进行索引,不涉及 Git 历史内容。
对比工具情况:
CodeBuddy:全项目文件索引,结合结构化记忆,检索范围覆盖整个项目,不局限于用户编辑过的文件。
Cursor:文件级向量索引,支持MCP协议关联本地文件系统,混合检索(语义+词法)功能,检索灵活性与精准度高,可通过插件实现本地无云端依赖检索。
Claude Code:云端向量化索引,支持千万行级别代码库检索,可跨项目检索相关内容,同时强化本地文件关联,提升与本地项目的融合度。
Codex / GitHub Copilot:无自建向量索引,依赖模型自身上下文理解能力,但结合企业级持久记忆,可实现仓库级精准上下文感知,无需主动检索即可关联项目相关内容。
Windsurf:全工作区跨文件索引,结合Cascade Agent,支持多步骤检索,可实现光标附近片段检索与全工作区检索结合,摆脱片段级索引的局限。
3. RAG 检索增强生成 🚀
Trae 的实现
Trae 采用标准 RAG 架构,是其核心竞争力,无需依赖云端服务,全程在本地完成检索与生成,兼顾效率与隐私安全。
检索:根据用户问题,从本地向量库与 SQLite 记忆库中联合召回相关代码、文档及会话记忆,结合时间线回溯还原上下文场景
增强:将召回的真实项目代码、记忆信息及规则约束注入生成 Prompt,确保生成内容与项目上下文一致
生成:LLM 基于项目真实结构与检索到的信息,输出符合规范的代码,支持跨文件、跨模块复杂需求开发
智能裁剪:自动压缩冗余上下文,筛选最相关的片段注入,避免 Token 超限,提升生成效率与准确性
对比:
CodeBuddy:已具备完善RAG能力,支持跨文件/跨模块检索增强,结合手动规则约束,可实现全局项目内容召回,不再局限于当前编辑的局部文件。
Cursor:云端RAG架构,同时支持本地持久记忆与MCP扩展内容联动,检索增强更贴合本地项目需求,响应速度大幅提升。
Claude Code:完善云端+本地混合RAG,联动双层文件记忆,支持团队共享检索资源,检索精准度与响应速度均有优化,可实现跨项目检索增强。
Codex / GitHub Copilot:已支持基础RAG功能,基于仓库级持久记忆实现检索增强,摆脱纯Prompt拼接模式,可主动关联项目中的相关内容。
Windsurf:具备完善RAG能力,基于全工作区跨文件召回,结合项目架构记忆,可实现多步骤检索增强,不再局限于光标附近片段检索。
4. 动态上下文注入 ⚡
Trae 的实现
Trae 在生成过程中能够融合多层级上下文,实现智能择优注入,确保生成内容贴合项目实际需求,同时避免冗余信息占用 Token。
可注入的上下文类型:
项目持久记忆:本地存储的项目全局记忆、文件级记忆及用户添加的规则信息
当前打开文件 / 光标附近代码:实时捕捉用户当前编辑的内容,优先注入相关片段
用户输入指令:精准匹配用户需求,注入与指令相关的上下文信息
手动引用文件(#file、#folder、#doc):支持用户主动指定需要注入的文件或文件夹,提升上下文精准度
机制:自动识别并择优注入最相关的上下文片段,支持代码、配置、文档、测试用例联合注入;同时通过智能裁剪算法,压缩冗余内容,保证模型高效利用上下文信息,避免 Token 浪费,提升生成响应速度与准确性,可通过 MCP 协议实现上下文与 AI agent 的灵活联动。
对比:
CodeBuddy:多层动态上下文注入,融合项目+用户双作用域记忆,支持跨文件上下文关联,不再仅依赖光标或当前打开文件的上下文。
Cursor:上下文注入机制,可跨会话召回上下文,结合MCP扩展实现多层上下文联动,融合本地持久记忆,与本地项目的融合度显著提升。
Claude Code:云端上下文注入,强化本地文件内容融合,结合双层文件记忆,可实现更精准的上下文注入,贴合本地项目实际需求。
Codex / GitHub Copilot:智能上下文注入机制,融合仓库级记忆与跨代理信息,摆脱纯Prompt拼接模式,可自动注入相关项目上下文。
Windsurf:函数级上下文注入,可感知终端输出、剪贴板内容等隐式上下文,同时支持项目全局记忆注入,不局限于函数级上下文。
5. 手动规则强化(TRAE Rules) 📏
Trae 的实现
Trae 支持通过 .trae/rules/ 目录下的 YAML/Markdown 文件定义规则,也可通过 IDE 右侧规则面板直接配置,规则可绑定具体目录或文件,实现精细化约束,确保生成代码符合个人习惯或团队规范,是 Trae 区别于其他工具的核心特色之一。
规则可约束的内容:
代码风格规范:如代码缩进、注释格式、代码颗粒度控制等
命名规范:类、函数、变量的命名规则,支持贴合不同项目的命名习惯
模块依赖限制:约束模块间的引用关系,避免无效依赖或循环依赖
安全与禁止 API:屏蔽不安全的 API 调用,降低代码安全风险
个性化偏好:如对话语言、编码工具偏好(如使用 pnpm 而非 npm)、AI 交互风格等
作用时机:生成前自动注入规则,引导模型按规范生成代码;生成后自动检查代码是否符合规则,确保规则落地执行。同时支持规则的版本化管理与团队共享,可通过 AI 辅助生成团队规范规则,降低配置成本。
对比:
CodeBuddy:已支持手动规则强化,可通过YAML/Markdown文件配置规则,支持Git共享,实现生成前后双重校验,可实现长期、稳定的规范管控。
Claude Code:支持通过CLAUDE.md文件配置手动规则,结合MEMORY.md自动记忆,形成规则与记忆联动,可实现生成前规则注入,但无专门的规则绑定与生成后自动检查机制,约束力度仍有提升空间。
Windsurf:在基础Lint集成基础上,结合Memories系统可读取项目规范记忆,实现基础规则约束,但仍无法自定义规则,约束灵活性不足,不支持规则注入与生成后校验。
6. Git 版本关联
Trae 支持读取 Git 状态,内置源代码管理功能,可初始化 GitHub 仓库、创建分支、推送/拉取代码,还能根据代码变更自动生成符合规范的 Git Commit 消息,提升版本管理效率;但不支持 commit 级别的历史回溯,无法检索 Git 历史中的代码内容与记忆信息,仅能关联当前工作区的 Git 状态。
对比工具情况:
CodeBuddy:支持Git共享结构化记忆与规则文件,可读取Git状态,辅助实现团队记忆与规范同步,但无Git历史追踪与commit级回溯功能;Cursor:无内置Git版本关联功能,但可通过MCP扩展实现Git相关联动;Windsurf:无Git版本关联功能,无法读取Git状态及进行相关操作。
Claude Code:支持云端记忆与 Git 历史文件追踪,记忆可提交至 Git 进行版本控制,可关联 Git 历史中的文件内容
Codex / GitHub Copilot:依托GitHub云端存储,可深度关联Git仓库,结合Copilot Memory实现仓库级记忆与Git状态联动,支持跨会话/跨代理共享,但无专门的Git操作功能与commit级历史回溯。
7. 横向对比表(最准确版本)
清晰对比6款工具核心能力,快速get各工具优势与短板:
| 能力维度 | Trae(真实情况) | CodeBuddy | Cursor | Claude Code | Copilot | Windsurf |
|---|---|---|---|---|---|---|
| 持久化记忆 | ✅ 项目级+全局本地持久记忆(SQLite+FTS5) | ✅ 项目+用户双作用域文件化持久记忆 | ✅ 原生本地持久记忆(JSON结构化) | ✅ 云端+本地双层文件记忆 | ✅ 企业级持久记忆(预览版) | ✅ 全项目级持久记忆 |
| 代码向量索引 | ✅ 全工作区索引,函数/类级检索 | ✅ 全项目文件索引,结构化记忆结合 | ✅ 文件级向量索引,混合检索 | ✅ 云端向量化索引,延迟优化 | ❌ 无自建向量索引,依赖仓库记忆 | ✅ 全工作区跨文件索引,多步骤检索 |
| RAG 能力 | ✅ 本地完整 RAG,跨文件召回 | ✅ 完善RAG,跨文件/跨模块检索增强 | ✅ 云端 RAG,低网络依赖,本地联动 | ✅ 云端+本地混合RAG,团队共享 | ✅ 基础RAG,基于仓库级持久记忆 | ✅ 完善RAG,全工作区跨文件召回 |
| 动态上下文 | ✅ 多层动态注入 + 智能裁剪 | ✅ 多层动态注入,跨文件关联 | ✅ 跨会话召回,多层上下文联动 | ✅ 云端上下文,强本地融合 | ✅ 智能上下文注入,摆脱纯Prompt拼接 | ✅ 函数级+全局记忆注入,多隐式上下文 |
| 自定义规则强化 | ✅ YAML/Markdown 规则,双重校验 | ✅ YAML/Markdown规则,Git共享,双重校验 | ❌ 无,仅 Prompt 约束 | ⚠️ 支持手动规则,无绑定与生成后校验 | ❌ 无,仅 Prompt 约束 | ⚠️ 基础 Lint 集成,无法自定义规则 |
| Git 版本关联 | ⚠️ 可读取 Git 状态,无 commit 回溯 | ⚠️ 支持Git共享记忆,可读取Git状态 | ⚠️ 无内置Git关联,可通过MCP扩展 | ⚠️ 云端历史追踪,Git 版本控制 | ⚠️ 关联Git仓库,无专门Git操作功能 | ❌ 无任何 Git 关联功能 |
Trae 采用极简本地化技术路线,不依赖大型向量数据库,专注于轻量、高效的项目记忆实现,适合注重隐私安全、需要本地高效开发的个人与团队;其局限性在于不支持 Git 历史全量索引与 commit 级回溯,在长期历史代码追溯场景中,相较于云端工具(如 Claude Code)略有不足。
8. 核心疑问解答:为何 Trae 功能全面,实际效果仍不及 Cursor 与 Claude Code?
结合前文对 Trae 及主流工具的能力对比,很多使用者会产生一个疑问:既然 Trae 在架构上覆盖了持久记忆、全量索引、RAG、动态上下文、规则强化等所有核心技术维度,看似支持的功能最多,实际使用体验尤其在刚上手使用时往往比不上 Cursor 和 Claude Code?这一问题的核心,在于理论功能与实际效果的差距,具体可从以下5个关键维度解析:
(1)模型能力本身的限制
Trae 的核心定位是 AI 开发工具平台,其核心价值在于整合完善的记忆与检索机制,但其代码生成质量很大程度上依赖于底层接入的 LLM 模型——国内版基于10万+中文技术文档和国内开源项目预训练,国际版涵盖亿级国际代码样本,但整体模型能力仍有提升空间。即便 Trae 的索引和 RAG 机制做得再精准,若底层模型在代码理解、自然语言解析、逻辑推理上存在短板,生成代码的准确性和智能程度也会受到限制。
反观 Cursor 和 Claude Code,二者均搭载了专属优化的高性能大模型:Cursor 背靠 Claude 、GPT 等第三方大模型,其内部使用的 Code LLM 经过专门优化,专注于代码生成场景;Claude Code 则直接使用 Claude 系列原生大模型,这些模型在自然语言到代码的转化、复杂上下文理解、逻辑推理能力上具备优势,因此直观感受上“效果更好”,直观感受上,国内的Code LLM 和Claude 、GPT相比有半年左右的差距。
总结:Trae 底层 LLM 的综合能力不及 Cursor 和 Claude Code 所搭载的 LLM 。
(2)实时上下文处理的效率差异
Trae 的动态上下文注入机制,需要经过“检索向量索引→召回相关代码→智能裁剪上下文→注入模型”的多步操作,虽然能保证上下文的完整性和准确性,但多步骤流程会导致处理延迟较高,有时无法及时捕捉到用户最新的编辑意图,影响交互流畅度。尤其当项目规模扩大至百万级文档时,向量检索的召回率会呈指数级下降,进一步影响处理效率。
Cursor 依托 IDE 内核直接操作,能够快速捕捉光标位置、当前文件上下文甚至用户最近几次的编辑操作,无需复杂的中间流程,生成速度快,交互体验更流畅,更贴合实时编码的需求;Claude Code 虽依赖云端模型,但其 RAG 与上下文融合经过端到端优化,能够在短时间内高效处理大量上下文信息,生成响应更迅速,给用户“更聪明”的直观感受。
总结:Trae 更注重上下文的完整性和准确性,却牺牲了部分实时性;Cursor 和 Claude Code 则在实时交互效率上做了重点优化,用户体验更流畅。
(3)数据与训练优化的差距
Trae 的核心优势集中在项目私有化知识存储和长期记忆沉淀,专注于贴合垂直项目的自定义需求,但在大规模公共代码语料的微调优化上有所欠缺——其训练数据主要聚焦于特定场景,缺乏全面的通用代码语料支撑。
Cursor 和 Claude Code 则依托庞大的开源代码语料库,结合内部大规模优化训练,在通用开发场景中表现更出色:无论是快速生成标准库代码、常见业务逻辑,还是解决各类边缘 bug、精准调用第三方 API,都能凭借丰富的训练数据实现更精准的生成;而 Trae 虽在垂直项目和自定义规则约束上表现突出,但在通用场景中,生成效果不如经过大规模训练的二者。
(4)用户体验与智能提示的优化侧重不同
Cursor 和 Claude Code 均将用户体验放在重要位置,在 UI/UX 设计和智能提示功能上做了大量针对性优化,例如实时代码补全、智能意图预测、代码错误修复建议、API 自动提示等,能够精准贴合开发者的编码习惯,降低操作成本,提升使用体验,让用户直观感受到“智能”。
而 Trae 的核心侧重是平台架构的完善和项目记忆的精细化管理,更偏向于项目级的规范管控和长期协作,在实时智能补全、个性化提示等细节体验上没有进行专门优化,导致用户在日常编码的直观感受上,不如 Cursor 和 Claude Code 便捷、智能。
(5)RAG 召回策略的优化差异
Trae 的 RAG 优势在于“准确”和“全量”,能够实现全工作区跨文件检索召回,确保检索结果的全面性,但在召回相关性排序、上下文裁剪策略上,缺乏端到端的深度优化,有时会出现召回内容冗余、核心信息排序靠后的问题,尤其在大规模知识库场景下,这一问题更为明显。
Claude Code 和 Cursor 则拥有经过大规模实践优化的“召回+生成”闭环,能够智能排序召回内容的相关性,精准裁剪冗余片段,同时将模型内隐知识与检索到的项目知识深度整合,减少无关信息的干扰,生成的内容更贴合用户需求,因此看起来更智能、更精准。
个人体验
通过长期使用,在摸透 Trae 脾气的基础上,配合简洁完善的全局 rule(不废话、不编造、不跑题)、project_rule(项目启动和测试方法、代码前先做计划、记忆本地记忆、执行过程输出日志),以及三段式提问公式(背景 + 需求 + 输出要求),可以获得非常流畅的开发体验,不反复,大部分情况下也能用一段要求跑通一个新项目。
现在用 Trae 开发已经很稳定,基本也不再折腾 Cursor 和 Claude Code 了。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~